

A OpenAI, responsável pelo ChatGPT, lançou recentemente uma avaliação chamada SimpleQA, desenvolvida para medir o quanto as respostas dos modelos de inteligência artificial são factualmente precisas. Os resultados, divulgados na última semana, indicam que, mesmo entre os modelos mais avançados, ainda há uma quantidade significativa de respostas incorretas.
Esse estudo evidencia as dificuldades que a IA enfrenta ao gerar respostas precisas, mostrando que, em diversas situações, as respostas erradas são dadas com muita confiança, o que levanta preocupações sobre a confiabilidade dessas tecnologias.
Desenvolvimento do SimpleQA
O SimpleQA é um benchmark desenvolvido para testar a capacidade dos modelos de IA de responder a perguntas diretas e objetivas com respostas que possam ser verificadas. A OpenAI destaca que, para as IAs, oferecer respostas factuais é um desafio complexo, pois a precisão de uma afirmação é difícil de medir em contextos amplos e variados.
Segundo a OpenAI, “modelos de linguagem podem gerar conclusões extensas com várias declarações factuais.” No entanto, o SimpleQA foca em consultas curtas e diretas, buscando dados concretos. Esse escopo mais restrito permite que a precisão seja avaliada de forma mais direta e controlada, facilitando a análise de como os modelos respondem a perguntas específicas.
Para assegurar a qualidade das respostas, a OpenAI contou com dois treinadores de IA independentes, que criaram um conjunto de 4.326 perguntas cobrindo temas variados, como ciência, política, cultura e tecnologia. Apenas perguntas em que as respostas dos dois treinadores coincidiam foram incluídas no benchmark, garantindo maior precisão. Um terceiro avaliador revisou 1.000 dessas amostras, confirmando uma taxa de concordância interna de aproximadamente 94,4%.
Na avaliação do SimpleQA, as respostas dos modelos de IA do ChatGPT são classificadas em três categorias: “corretas,” “incorretas” e “não respondidas.” A categoria “não respondida” é especialmente importante, pois verifica se os modelos conseguem reconhecer quando não possuem uma resposta precisa, evitando a geração de informações possivelmente incorretas.
Desempenho dos Modelos da OpenAI: Resultados e Análises
Nos testes realizados, a OpenAI submeteu diferentes versões de seus modelos ao benchmark SimpleQA, o que trouxe à tona diferenças notáveis de precisão, variando conforme o tamanho e o design de cada modelo.
Os modelos menores, como o GPT-4o-mini e o o1-mini, tiveram taxas de acerto mais baixas, algo esperado pela OpenAI devido ao conhecimento de mundo mais limitado dessas versões. O ponto que mais chamou atenção, porém, foi a alta taxa de respostas incorretas entre todos os modelos avaliados.
Os resultados detalhados foram os seguintes:
- GPT-4o-mini: alcançou 8,6% de respostas corretas, 0,9% de respostas não respondidas e 90,5% de respostas incorretas.
- o1-mini: apresentou 8,1% de respostas corretas, 28,5% de respostas não respondidas e 63,4% de respostas incorretas.
- GPT-4o: obteve 38,2% de respostas corretas, 1,0% de respostas não respondidas e 60,8% de respostas incorretas.
- o1-preview (modelo mais avançado): registrou 42,7% de respostas corretas, 9,2% de respostas não respondidas e 48% de respostas incorretas.
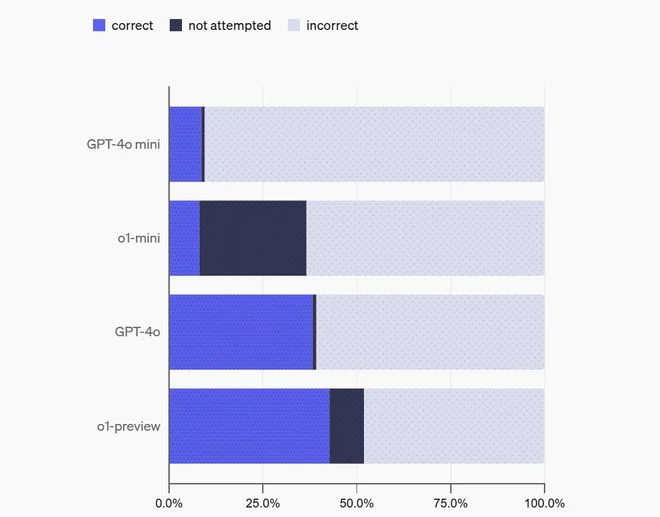
A OpenAI destacou que modelos como o o1-mini e o o1-preview, projetados para “refletirem” mais antes de responder, mostraram uma tendência maior a optar por “não responder” em comparação com versões como o GPT-4o-mini e o GPT-4o. Isso sugere que modelos com capacidade de raciocínio aprimorada conseguem reconhecer quando não possuem uma resposta confiável, evitando, assim, a criação de respostas potencialmente incorretas e fantasiosas.
Ainda Distantes da Precisão Factual
Os resultados do SimpleQA evidenciam os desafios que a OpenAI e outras empresas enfrentam ao tentar melhorar a precisão factual de seus modelos de linguagem de IA generativa.
Um dos principais obstáculos é a confiança excessiva que esses modelos demonstram em respostas incorretas, o que dificulta a utilização dessas ferramentas em situações que demandam alta confiabilidade e precisão informativa. Embora a habilidade de um modelo em reconhecer suas limitações e optar por não responder represente um avanço significativo, essa capacidade ainda é insuficiente em várias versões testadas.
A OpenAI reconheceu que, apesar dos progressos feitos até agora, alcançar a total precisão factual ainda é um objetivo que está longe de ser alcançado. A empresa propõe que os desenvolvimentos futuros devem se concentrar não apenas na ampliação do conhecimento dos modelos, mas também na melhoria de sua habilidade de avaliar a veracidade das informações antes de fornecer uma resposta.